
关于树这个主题, 网上已经有非常多资料了, 本文尝试汇总一下各种树的适用场景, 对于每种树的技术原理做大致描述, 同时链接一些优秀的介绍文章
树的一家
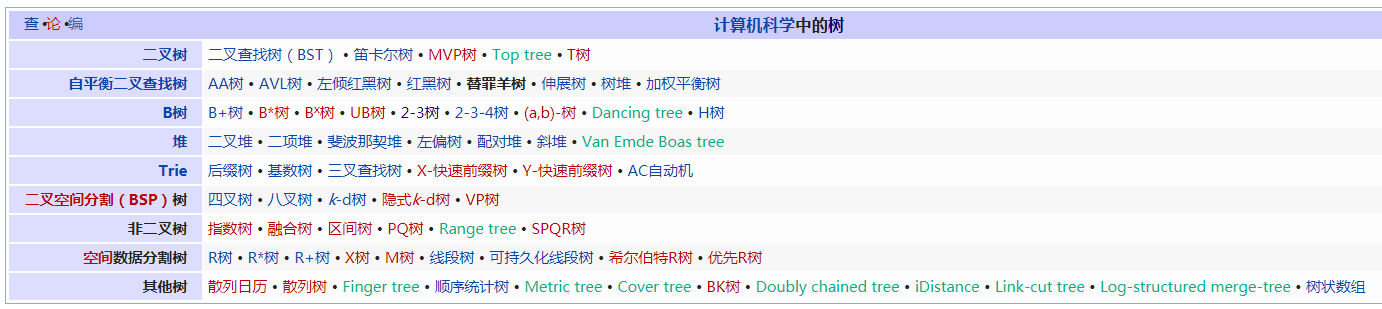
首先放一张维基上的树的家谱
树的基本结构
| 树是由节点和边组成的数据结构, 参考 [Tree Data Structures in JavaScript for Beginners | Adrian Mejia | JavaScript, Algorithms and Web development Tutorials](https://adrianmejia.com/data-structures-for-beginners-trees-binary-search-tree-tutorial/) 以及翻译版 初学者应该了解的数据结构: Tree - 众成翻译 |
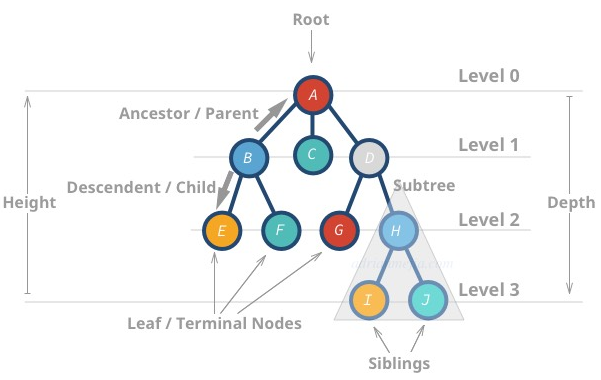
基本术语
- 最顶层节点叫
根节点(root node), 即没有任何父节点的节点 - 没有任何子节点的节点被称为
叶节点(leaf node) - 树的
高度(Height) 是最深的叶节点与根节点之间的距离 例如, 节点 A 的度是 3, 节点 I 的度是 0 - 节点的
深度(Depth) 是节点与根节点的距离 例如, 节点 H 的深度是 2, 节点 B 的深度是 1
应用场景
树是许多高级数据结构的基础, 在以下场景中有广泛应用:
- Maps, Sets, 队列
- 数据库
- 在 LDAP (Lightweight Directory Access Protocol) 中查找相应信息
- 在 XML/HTML 文件中, 使用文档对象模型(DOM)接口进行搜索
二叉树
树的每个节点最多只有两个子节点时就是二叉树
二叉树的特殊属性
- 满二叉树: 任意一个节点只有零或两个子节点
- 完全二叉树: 若二叉树的高度为h, 除第h层外, 其它各层的节点数都达到最大个数, 第h层所有节点都连续集中在最左边
- 完美二叉树: 满足完全二叉树性质, 树的叶子节点均在最后一层
- 平衡二叉树: 当树有 N 个节点时, 高度不超过
O(log N), 例如 AVL 树, 红黑树
满二叉树的样例
18
/ \
15 30
/ \ / \
40 50 100 40
18
/ \
15 20
/ \
40 50
/ \
30 50
18
/ \
40 30
/ \
100 40
完全二叉树的样例
18
/ \
15 30
/ \ / \
40 50 100 40
18
/ \
15 30
/ \ / \
40 50 100 40
/ \ /
8 7 9
这些属性有什么用呢? 基本都是在考察树的平衡性, 后面可以看到, “平衡” 的树查找效率较高, 所以这些属性都是为了实现高性能
树的性能
所有的树都需要考虑三个基本操作 查找节点, 插入节点, 删除节点 的性能, 每种操作都包括 平均性能 和 最差情况的性能
在选择使用何种树时, 需要结合特定的使用场景, 如果应用场景未知, 其重要性排序可能是 查找节点 > 插入节点, 在一般的介绍文章里 删除节点 的性能似乎较少提到, 对于某些场景删除节点也是很重要的
实现基本的树
这部分拆出来, 放在配套的代码文章里
二叉搜索树, BST
二叉搜索树也叫有序二叉树 / Binary Search Tree / BST, 二叉搜索树的定义是节点的所有左孩子都比节点自身小或相等, 右孩子都比节点自身大, 如:
10
/ \
6 30
/ / \
4 15 40
/ \
3 5
优势
因为每次查找时都能把范围缩小到一半, BST 的查找和插入操作都很快, BST 查找一个节点平均时间复杂度为 O(log N), 因此该数据结构适用于需要多次插入/查找数据的场景, 特殊情况时查找会慢很多
注: BST 通常不允许重复值的节点被添加到树中, 这时因为插入的是 “键”, 类似 ID, 同样的键代表同一份数据, 如允许重复值, 重复节点应该作为右子节点, 有些 BST 的实现会记录重复的情况
缺点
插入操作没有尝试平衡树, 最坏的情况下, 比如升序插入数据之后, 树可能只向某一个方向生长, 使之退化为链表, 查找复杂度变为 O(n), 这时就需要改进树结构来解决问题
树的遍历
任何树都需要实现遍历, 但针对 BST 的遍历能较好的体现几种遍历的区别
中序遍历 (In-Order Traversal)
中序遍历访问节点的顺序是: 左子节点、节点本身、右子节点
以这棵树作为例子:
10
/ \
5 30
/ / \
4 15 40
/
3
中序遍历将按照以下顺序输出对应的值:
3、4、5、10、15、30、40
也就是说, 如果待遍历的树是一颗二叉搜索树, 那输出值将是升序的
后序遍历 (Post-Order Traversal)
后序遍历访问节点的顺序是: 左子节点、右子节点、节点本身
后序遍历将按照以下顺序输出对应的值:
3、4、5、15、40、30、10
先序遍历 (Pre-Order Traversal) 与 深度优先搜索 (DFS)
先序遍历访问节点的顺序是: 节点本身、左子节点、右子节点
先序遍历将按照以下顺序输出对应的值:
10、5、4、3、30、15、40
先序遍历与深度优先搜索(DPS)的顺序一致
广度优先搜索 (BFS)
BFS 将按照以下顺序输出对应的值:
10、5、30、4、15、40、3
AVL 树
从这里开始是实践中会用到的几种树
之前说过 BST 虽然在大多数情况下运行良好, 但在顺序插入元素的情况下就变成链表了, 性能会大打折扣, 于是我们需要在树的结构不够好时, 能够自动修复平衡性
AVL 树是较早期出现的一种自平衡的二叉搜索树, 得名于其发明者 (Adelson-Velskii 和 Landis), 其基本思想是, 时刻监视树的平衡性, 当插入节点导致失衡时, 就立即做一次平衡性修复, 保证平衡度时刻处于可以接受的范围内
AVL 树的递归定义:
- 左右子树的高度差小于等于 1
- 其每一个子树均为 AVL 树
AVL 树的时刻平衡
AVL 树一旦数据插入导致树结构不平衡时, 则马上就要进行调整, 为什么需要时刻调整平衡呢? 如果不去时刻维护, 以后再要获得全局信息代价高昂, 且全局调整难度大于局部调整
AVL 树的平衡调整操作
AVL 树的平衡化有两大基础操作: 左旋和右旋, 左旋即逆时针旋转, 右旋即顺时针旋转, 这两种操作是对称的
当 AVL 树结构变化, 比如插入和删除节点, 需要考察受影响节点的 平衡因子 (Balance Factor, 某个节点的左子树的高度减去右子树的高度差), 如果超过阈值就进行旋转, 这种旋转在整个平衡化过程中可能进行一次或多次, 这两种操作都是从失去平衡的最小子树根节点开始的 (即离插入节点最近且平衡因子超过1的祖节点)
以右旋为例, 右旋操作就是把上图中的 B 节点和 E 节点进行 “父子交换”, 在仅有这三个节点时很简单
E
/
B B
/ / \
A A E
但是, 当B节点处存在右孩子时, 稍有点复杂, 通常操作是抛弃右孩子, 将其与旋转后的节点E相连, 成为节点E的左孩子
E
/
B B
/ \ / \
A C A E
/
C
左旋的场景是完全对称的
AVL 树将需要平衡的场景归结为以下四种:
LL 型
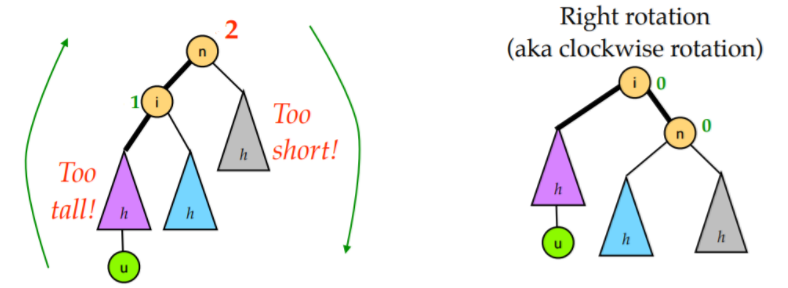
LL 型就是上图左边那种情况, 因为在根节点的左孩子的左子树添加了新节点, 导致根节点的平衡因子变为+2, 二叉树失去平衡, 这种情况对节点n右旋一次即可
RR 型
RR 型的情况和 LL 型完全对称, 只需对节点n进行一次左旋即可修正
LR 型
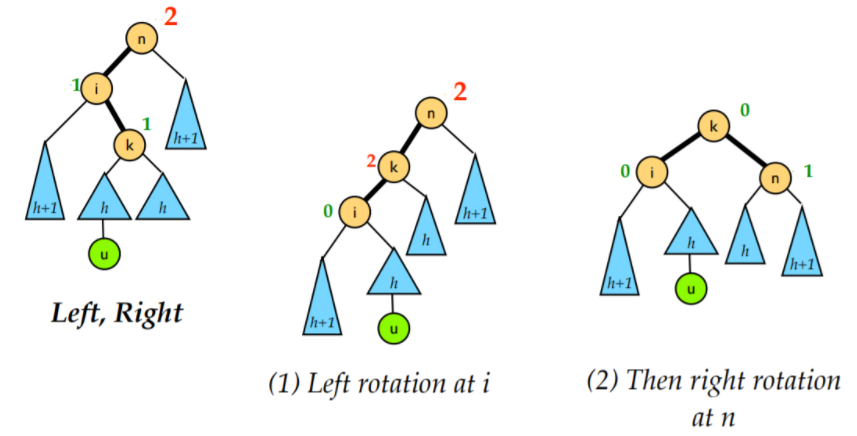
LR 是将新的节点插入到了n的左孩子的右子树上导致的不平衡的情况, 需要先对 i 进行一次左旋, 再对 n 进行一次右旋
RL 型
RL 是将新的节点插入到了 n 的右孩子的左子树上导致的不平衡的情况, 需要先对 i 进行一次右旋, 再对 n 进行一次左旋
这四种情况的判断很简单, 根据破坏树的平衡性(平衡因子的绝对值大于 1)的节点以及其子节点的平衡因子来判断平衡化类型
可得出如下表格:
| 问题节点 | 左孩子 | 右孩子 | 类型 |
|---|---|---|---|
| +2 | +1 | - | LL |
| +2 | -1 | - | LR |
| -2 | - | +1 | RL |
| -2 | - | -1 | RR |
AVL 插入新节点所需要的最大旋转次数是常数, 不需要一直旋转到根节点, 这里参考 AVL 树的谣言
根据 AVL 的定义, 可以做出两个推论, 再平衡向上回溯时:
- 对于插入更新, 如当前节点的高度没有改变, 则上面所有父节点的高度和平衡也不会改变
- 对于删除更新, 如当前节点的高度没有改变且平衡值在
[-1, 1]区间, 则所有父节点的高度和平衡都不会改变
根据这两个推论, AVL 的插入和删除大部分时候只需要向上回溯一两个节点即可, 范围十分紧凑
这个说法对吗? 为什么?
多路查找树 (N叉查找树)
如果在树的节点上做文章, 自然会想到采用 “多叉” 的结构, 让每一个节点的孩子数可以多于两个, 且每一个节点自身也可以存储多个元素, 这样就形成了多路查找树
从本质上, BST 节点把空间分割为两半, 而多路查找树的节点把空间分为 N 个部分, 当然由于它是查找树, 元素间还是需要存在排序关系
多路查找树常见的几种形式:
- 2-3树
- 2-3-4树
- B树
- B+树
后面可以看到, 多路查找树比 BST 更合适用在硬盘中, 这是由于二叉查找树的节点只具有两个子节点, 节点数量多时必然导致树的深度很大, 在内存中这没问题, 但在硬盘中随机访问数据的耗时很长, 如果每次都沿着路径把过程节点挨个访问一遍, 这个开销是不能接受的
2-3查找树
允许节点保存一到两个键
2-节点: 就是普通的 BST 节点, 含有一个键和两条链接, 左链接都小于该节点, 右链接都大于该节点3-节点: 含有两个键和三条链接, 左链接都小于该节点, 中链接都位于该节点的两个键之间,右链接都大于该节点
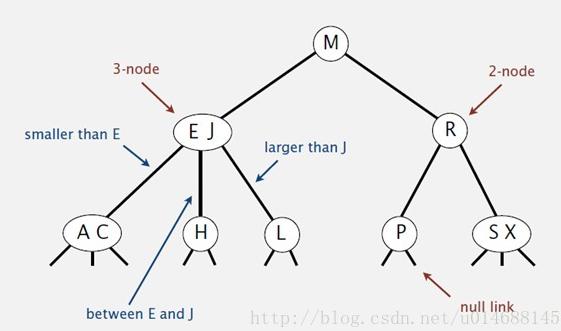
设计缘由
为什么 2-3查找树能够实现平衡呢?
回到 BST 的设计, BST 最大的问题在于对输入敏感, 在插入数据恰好是有序的情况下, BST 构建出来的结构相当于是链表, 本质是当新节点加入时, 树没有选择 “节点去向” 的权力, 自然就没办法动态改变它的高度, 所以需要设计一种结构能够让树拥有分配权, 且可以动态调整自身结构
而在 2-3查找树中, 2-节点即传统的 BST 节点,而新引入的 3-节点, 意味着树可以把新加入的节点 “暂存在这”, 此后当满足一定条件时就可以在保证平衡的同时分裂, 这样就拥有了灵活的调整手段
对 2-3查找树操作的基本原则
查找: 跟普通二叉树道理相似, 但是多一个分支, 判断条件会稍微复杂一点儿
插入:
- 不允许向末端插入, 否则会破坏平衡
- 当有新的元素插入时, 首先找到对应叶子节点, 如果有空余就直接存放 (生成一个3-节点)
- 新元素插入, 且叶子节点没有空余就分裂, 把分裂出来的新节点上浮到父节点中
- 上浮到父节点的过程可能会继续向上传导
在2-3树中, 只有唯一的情况会导致树高度增加: 即插入元素后, 分裂向上传导到根节点, 使根节点也分裂, 此时树高度+1, 按照这个原则, 2-3树永远是平衡的
3-节点的分裂
A E <---- 这时新加入 S
/ | \
A E S <---- 形成临时的 4-node
/ | | \
E
/ \
A S <---- 分裂
/ \ / \
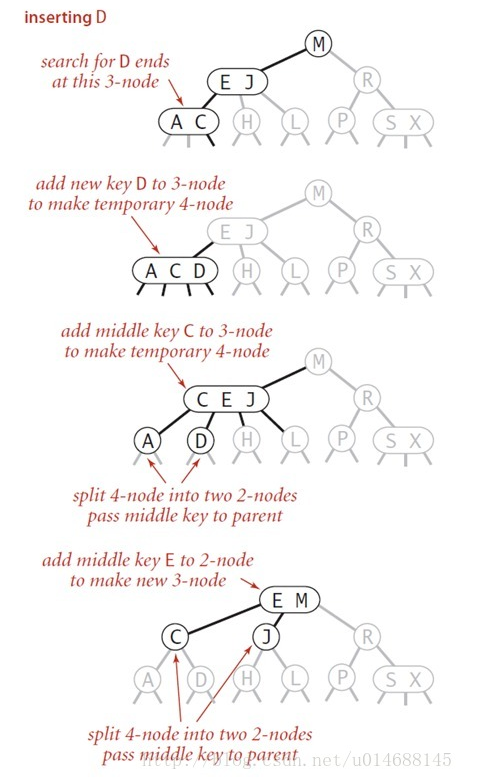
这种树想删除节点时怎么办?
优势
2-3树在最坏情况下仍有较好的性能, 每个操作处理每个节点的时间都不会超过一个很小的常数, 且这两个操作都只会访问一条路径上的节点, 所以任何查找或者插入都不会超过对数级别
完美平衡的2-3树非常平展, 例如含有10亿个节点的2-3树的高度仅在19到30之间, 最多只需要访问30个节点就能在10亿个键中进行任意查找和插入操作
缺点
需要维护两种不同类型的节点, 查找和插入操作的实现需要大量的代码, 而且它们所产生的额外开销可能会使算法比标准二叉查找树更慢, 平衡一棵树的初衷是为消除最坏情况, 但我们希望这种保障所需的代码能够越少越好
2-3-4树
跟 2-3树类似, 允许节点保存1到3个元素
- 2-节点: 包含 1 个元素和 2 个分支
- 3-节点: 包含 2 个元素和 3 个分支
- 4-节点: 包含 3 个元素和 4 个分支
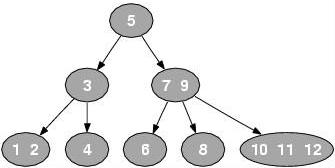
2-3-4树的查找: 跟 2-3树没什么本质区别
2-3-4树的插入: 同样不允许向空叶子插入, 这样就能保证所有的叶子都处在同样高度, 插入时首先尝试合并入叶子节点, 没有空间时 (向 4-节点插入时) 先把叶子节点分裂, 上浮叶子节点中间的那个元素, 再递归处理上浮
2-3-4树也是只允许通过根节点分裂增加高度, 这是唯一使树的高度+1的情况
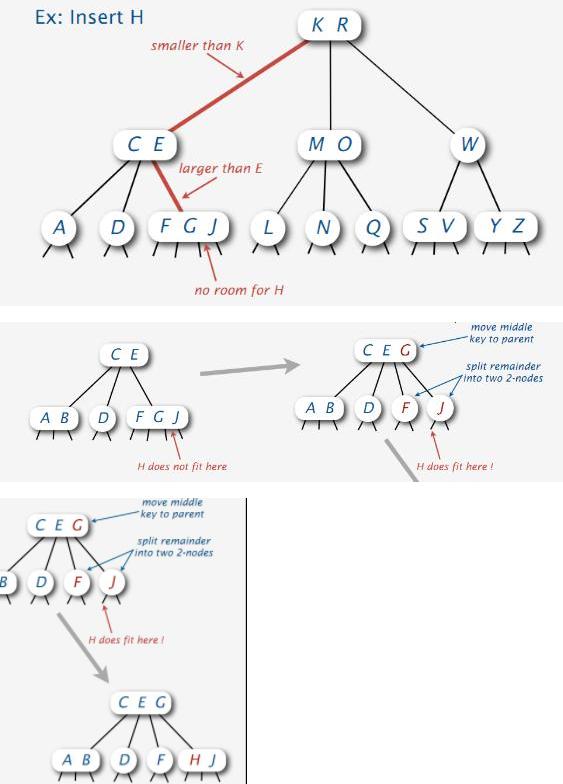
节点超负荷时的处理
2-3树: 在3-节点中插入元素时, 会形成临时的 4-节点, 然后上浮中央的元素, 称作 bottom-up 2-3
2-3-4树: 在4-节点中插入元素时, 需要先分裂成三个 2-节点, 称作 top-down 2-3-4
两者的本质是一样的
红黑树
据说作者 Robert Sedgewick 正遇到刚发明激光彩色打印机, 觉得打出的红色很好看, 就用了红色来区分节点, 于是叫红黑树
红黑树规则如下:
- 每个节点不是红色就是黑色
- 根节点总是黑色
- 如果节点是红色, 则它的子节点必须是黑色, 反之不一定
- 从根节点到叶节点或空子节点的每条路径, 必须包含相同数目的黑色节点, 即相同的黑色高度
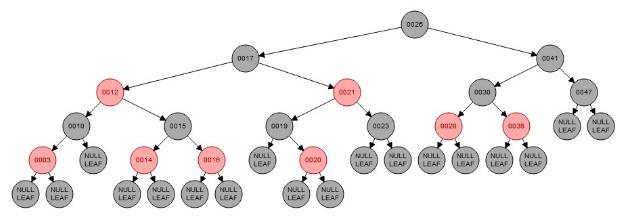
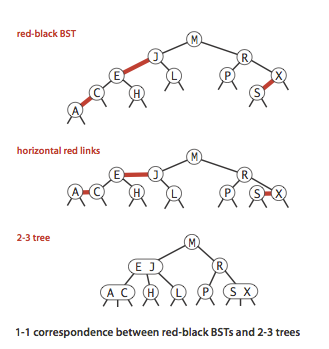
红黑树的起源是 “2-3-4树”, 从2-3-4树谈到Red-Black Tree, 红黑树其实是以二叉树的形式来描述 2-3-4树, 这样就可以复用已经写好的二叉树代码, 然而 2-3-4树节点内部可以有多个元素, 所以就用红色线把节点内部的数字连接起来, 而节点之间就用黑色线连接, 同时它还是表现为二叉树的形式, 可兼容原先的查找操作, 这就是红黑树的来历

红链接 vs 红节点
讨论红黑树时, 有些人习惯使用 “红链接”, 另一些习惯使用 “红节点”, 两者本质是相同的
在原理上, 红链接更容易理解, 红链接意味着 “内部链接”, 可以把红链接的父子两节点视为一个 “大型节点”
在实现上, 标记节点颜色比标记链接颜色更容易, 所以在代码中一般都是对节点染色, 约定 “红节点” 指 “从父节点到这个节点的链接是红色”
左倾红黑树
1978年 Guibas 和 Sedgewick 发明最初的红黑树, 2008年 Sedgewick 对其进行了改进, 并将此命名为 LLRBT (Left-leaning red–black tree 左倾红黑树), LLRBT 相比原版红黑树要简单很多, 实现的代码量也少 LLRB.pdf
左倾红黑树通过把链接标记为红色黑色来模拟 3-节点, 继承的是 2-3树的思想, 但在实现中所有的节点都是标准的二叉树节点, 免去了维护两种节点的麻烦
存疑, 这个可能还是跟2-3-4树有关
A B 2-3树
/ | \ 示例一个 3-节点
/ | \
B 左倾红黑树, 双线为红色链接
// \ 含义: 节点A和节点B是不可分割的整体
// \ 这里 "A+红线+B" 等于2-3树中的 "3-节点"
A
/ \
/ \
B 左倾红黑树的另一种表示
/ \ 不标记链接颜色, 改为标记红色节点
/ \ 这里 "黑节点+红节点" 表示 "3-节点"
*A* 也可以理解为由黑指向红节点的链接是红链接
/ \
/ \
左倾红黑树规则如下:
- 红链接均为左链接 (如果既可能是左链, 又可能是右链, 需要维护的情况就增多了, 不利于理解)
- 任何一个节点都不许有两条红链接 (否则会出现4-节点, 就变成了标准红黑树, 需要用改色消除这种情况)
- 如果节点是左侧红链接, 则节点的左孩子不能再是左侧红链接 (早期这样表示一个4-节点, 现在已经弃用, 需要以旋转消除这种情况)
- 该树是完美黑色平衡, 任意空链接到根节点的路径上的黑链接数量相同 (若去除颜色, 它不是算平衡树, 若把红色链接铺平, 黑色链接是完美平衡的)
在看资料前, 一定要分清作者在讨论红黑树还是左倾红黑树, 算法第四版的红黑树实际上是左倾红黑树
改色
左倾红黑树有一个改色操作, 目的是为了消除红色节点在右侧的情况, 改色在原版红黑树中并不存在
意味着当看到 “改色”, 说明这必然是左倾红黑树?
插入元素
类比2-3-4树的插入会更容易理解, 首先讨论简单的情况, 向2-节点中插入节点:
向2-节点中插入节点, 红黑树的做法:
情况 1, 向 D 插入 C:
D
//
C <- C自然放在左侧, 且C要标记为红色 (这里假设 D 是黑色)
情况 2, 向 C 插入 D:
C D
\\ => //
D C <- 违反了 "红链接均为左链接", 需要做一次左旋修复
向2-节点中插入节点, 相应的2-3-4树中的做法:
C C D
/ \ => / | \ <- 无论哪种情况, 都形成了一个 3-节点
然后讨论复杂的情况, 向3-节点中插入节点:
向3-节点中插入节点, 红黑树的做法:
情况 3, 插入 A (对 H 右旋, 形成临时的双红链接)
H H
// // C
C => C => // \\
// A H
A
情况 4, 插入 C (对 A 左旋, 再对 H 右旋, 形成临时的双红链接)
H H H
// // // C
A => A => C => // \\
\\ // A H
C A
情况 5, 插入 H (直接插入, 形成临时的双红链接)
C C
// // \\
A => A H
向3-节点中插入节点, 相应的2-3-4树的做法:
上述 3 4 5 三种情况都一样, 都是形成一个临时的 4-node
X Y A C H
/ | \ => / | | \
之后, 因为左倾红黑树不允许左右孩子都为红色, 在形成临时的双红链接之后还需要改色:
对上述 3 4 5 三种情况的临时的双红链接, 需要把红链接提上去 (可能出现递归)
/ //
C C
// \\ => / \
A H A H
等价于 4-节点分裂为 2-节点
A C H => C
/ | | \ / \
A H
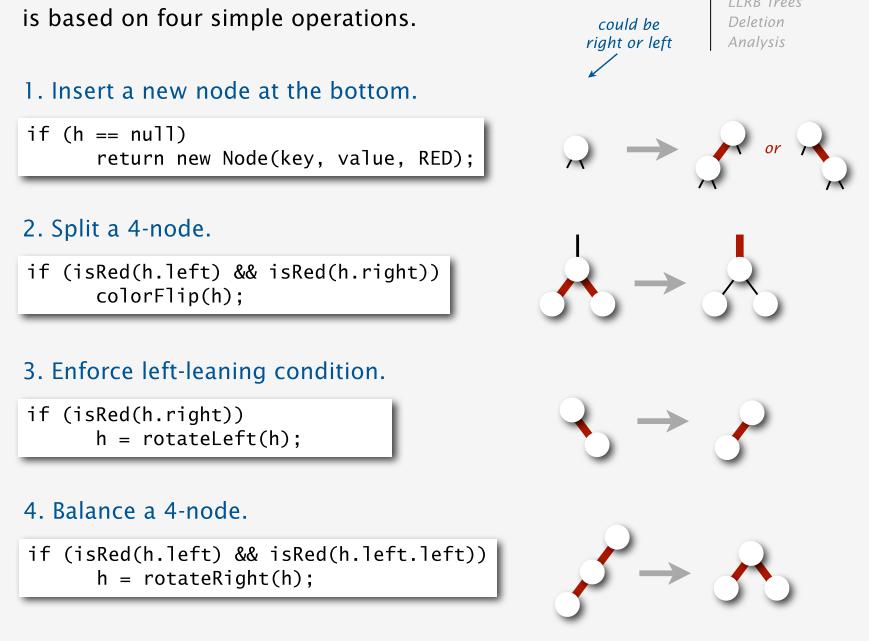
总结左倾红黑树插入元素的步骤是:
可以将插入元素的步骤划分为四种基本操作
- 插入元素 (红链接可能出现在两侧)
- 分裂4-节点
- 修复为左倾
- 平衡4-节点
插入节点设为红色
如果父节点是黑色:
如果插入节点是父节点的第一个孩子:
插入节点在左侧, 什么都不做 (情况 1)
插入节点在右侧, 需要旋转到左侧 (情况 2)
如果父节点之前有一个孩子:
之前的孩子必然是红色和左侧, 而插入节点在右侧, 完后需要改色 (情况 5)
如果父节点是红色:
(这时祖父必然是黑色, 且父节点必然在祖父的左侧)
如果 "祖父 -> (左) 父 -> (左) 插入节点", 对祖父右旋, 改色 (情况 3)
如果 "祖父 -> (左) 父 -> (右) 插入节点", 对父节点左旋, 再对祖父右旋, 改色 (情况 4)
改色可能向上传递, 需要维护整条链上的颜色都符合规范
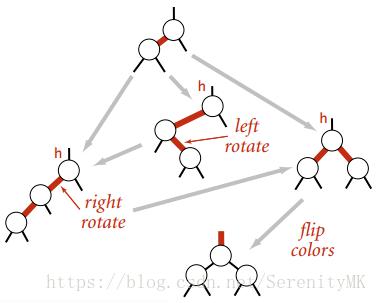
注: 如果这里将递归向上的最后一步改色操作, 延迟到下次插入操作之前, 这样插入完成后树中将存在4-结点, 生成2-3-4树
这两个文档有对左倾红黑树插入删除节点的较详细的描述: 左倾红黑树的C++实现 和 理解红黑树
删除元素
总结规律是:
找到被删节点的后继节点, 以后继节点的key替换被删节点的key, 之后删除后继节点
如果删的后继节点是红的, 不会影响红黑树的性质 如果删的后继节点是黑的, 要把它变成红的
AVL 和 红黑树区别
结构和实现
- 红黑树: 保存红黑状态, 每个节点只需要一位二进制, 也就是一个 bit
- AVL 树: AVL 每个节点需要额外存储一个平衡值
在具体实现时, 红黑树记录颜色的这个 bit 可以塞到其他地方, 就可以不占用额外空间了, 而 AVL 树的平衡值可以用两个 bit 来存储, 然后塞到指针里
指针少了两个 bit 有什么后果?
- 红黑树: 复杂, 插入有5种情况, 删除有6种情况, 代码量大, 编写容易出错
- AVL 树: 相对简单
平衡度
- 红黑树: 没有一条路径会比其他路径长两倍以上, 近似平衡
- AVL 树: 树高差最多只有 1, 严格平衡
红黑树的树高度, 最坏 2log(n), 平均 log(n)
操作
- 红黑树: 旋转次数较少, 但是需要染色
- AVL 树: 旋转次数多, 只要插入或删除不满足条件就旋转
据说优化过的 AVL 和 Linux 的 RBTree 差不多, 待确认
如果插入一个 node 引起了树的不平衡,AVL 和 RB-Tree 都是最多只需要 2 次旋转操作,即两者都是 O(1);但是在删除 node 引起树的不平衡时,最坏情况下,AVL 需要维护从被删 node 到 root 这条路径上所有 node 的平衡性,因此需要旋转的量级 O(logN),而 RB-Tree 最多只需 3 次旋转,只需要 O(1) 的复杂度。
其次,AVL 的结构相较 RB-Tree 来说更为平衡,在插入和删除 node 更容易引起 Tree 的 unbalance,因此在大量数据需要插入或者删除时,AVL 需要 rebalance 的频率会更高。因此,RB-Tree 在需要大量插入和删除 node 的场景下,效率更高。自然,由于 AVL 高度平衡,因此 AVL 的 search 效率更高。
map 的实现只是折衷了两者在 search、insert 以及 delete 下的效率。总体来说,RB-tree 的统计性能是高于 AVL 的。
适用场景
- 红黑树: 适合插入删除频繁的情况
- AVL 树: 由于旋转耗时, 适合插入删除次数比较少, 但查找多的情况
复杂度分析
有个挺常见的表
| 数据结构 | 最坏情况 | 平均情况 |
|---|---|---|
| – | 查找 / 插入 | 查找 / 插入 |
| 无序链表 | N , N |
N/2 , N |
| 有序数组 | lg(N) , N |
lg(N) , N/2 |
| 二叉搜索树 (BST) | N , N |
1.39lg(N) , 1.39lg(N) |
| 2-3树, 红黑树 | 2lg(N) , 2lg(N) |
1.00lg(N) , 1.00lg(N) |
为什么?
无序链表的复杂度解释
如果无序链表是在尾部插入的, 那么跟表中提供的数据符合
但是, 顺序查找的插入为什么是 N, 直接插入在首节点不好吗?
有序数组的复杂度解释
这个好理解, 有序数组的查找没有好坏之分, 永远是折半查找
有序数组的插入需要调整节点, 期望是要动一半的节点, 最不利时要动所有节点
二叉搜索树的复杂度解释
最坏情况其实就是退化为链表的情况, 好理解
对于平均情况的 1.39lg(N) 的解释:
首先, lg() 一般都是表示以 10 为底, 但这里应该是表示以 2 为底, 换算公式是 lg(x) = ln(x)/ln(2)
若BST完美平衡, 则查找复杂度应该是 lg(N), 但是实际平衡度是介于完美平衡和极度不平衡之间的, 这里给出的结果是 1.39lg(N), 这个 1.39lg(N) 是这么算出来的:
2 x ln(N) = 2 x ln(2) x log(N, 2) = 1.386438 x log(N, 2) = 1.39lg(N)
为什么在平均情况下, 二叉搜索树的查找/插入复杂度是 2ln(N)? 参考 http://cse.iitkgp.ac.in/~pb/algo-1-pb-10.pdf 的证明, 简要总结如下:
首先需要定义四个值…
E
/ \
/ \
C F <---- Internal node
/ \ / \
/ \ # # <---- External node
A D
/ \ / \
# B # #
/ \
# #
Internal path length: I(n) 所有内部节点 (正常节点) 到根节点的距离之和External path length: E(n) 所有外部节点 (无数据的 dummy 节点) 到根节点的距离之和Average number of comparisons for successful search: S(n) 命中查找的平均比对次数Average number of comparisons for unsuccessful search: U(n) 没能命中查找的平均比对次数
之后可得:
S(n) = (I(n) + n) / n 命中查找的次数的期望 = 内部节点的平均距离 + 1
U(n) = E(n) / (n + 1) 没有命中的查找的次数的期望, 这里为什么是 n+1 ?
E(n) = I(n) + 2n 外部节点距离和 = 内部节点距离和 + 2n, 这个可以递推出来:
每增加一个内部节点, 设其深度是 h, 则 dI = h, dE = 2h+2 - h,
所以每增加一个内部节点, dE - dI = 2
这三个联合起来, 可以得出 S(n) 的公式, 备用
然后, 考虑树的构建顺序, 设新加入的数据x被存放在树的第i个节点 (该节点记作 u[i]), 则插入这个数据时, 肯定首先执行过一次 “没有命中的查找”, 次数是 U(i-1)
一旦插入了数据x, 则再次查找数据x时, 就会在节点 u[i] 这里终止, 因此, S(i) = U(i-1) + 1, 多出来的那一次查找, 是因为需要区分命中查找和没命中的查找
考虑 “依次向树上添加节点” 的整个过程, 则可以认为在总体情况下, 平均查找次数 S(n) 是
上面两个大式子联合起来是:
将 n 设为 n-1 则是:
相减得到 U(n) 的递推公式:
其中 U(0) = 0, 将递推改写成通项公式是
H(n) 表示第n个 调和级数, 这是个发散极其缓慢的级数, 且第n个调和数与n的自然对数的差值收敛于 欧拉-马斯刻若尼常数 (约为 0.577), 参考 调和级数 和 欧拉-马斯刻若尼常数
有了 U(n), 自然也就有了 S(n), 在n很大时, 这两个值没什么区别, 都是 2ln(N)
简要总结完了…
红黑树的复杂度解释
为什么是 2lg(N) 和 1.00lg(N)?
爱是啥是啥吧, 先不弄了 …
二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
跳表
现在部分场景使用跳表来替换红黑树
跳表 skiplist:
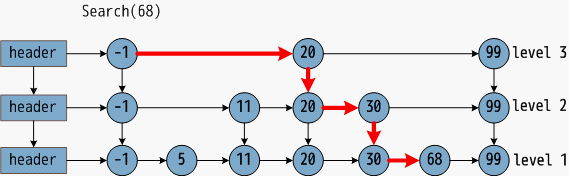
跳跃列表是按层建造的, 底层是个普通的有序链表, 每个更高层都充当下面列表的 “快速通道”, 查找目标元素时从顶层列表的头元素起步, 沿着每层链表搜索, 直至找到一个大于或等于目标的元素
如果该元素大于目标元素或已到达链表末尾, 则退回当前层的上一个元素, 转入下一层进行搜索
跳表第i层中的元素按概率p (通常为1/2或1/4) 出现在第i+1层中, 选择不同p值可以在查找代价和存储代价之间获取平衡
- 操作时间复杂度和红黑树相同
- 代码实现更易读
- 区间查找效率更高
缺点
- 内存占用比红黑树大(每节点 4 指针)
- 由于插入时是随机选择 level,cache 友好性不够好
以上这些树结构和跳表都是适合内存的数据, 如果是放在磁盘中, 插入和删除时重新平衡的开销很大, 适合磁盘的数据结构是B树系列
树堆
随机平衡二叉查找树, 树堆 Treap = Tree + Heap
Treap本身是二叉搜索树, 其左子树和右子树也分别是一个Treap, Treap记录了一个 “优先级”
优点: 插入删除简单直观, 速度也不错, 很好地平衡了编码复杂度和时间效率
缺点: 由于优先级(优先级是个堆)是随机生成的, 所以只能保证它的插入和删除操作时间复杂度大概是log(N),不能期待它的操作一定能在准确时间内完成
所以Treap常用于算法竞赛需要手写BST时, 尤其是扩展而来的Rank Tree(名次树, 查询第k大的元素, set做不了)
B树
B 即 Balanced, B树是一种平衡的多路查找树, 2-3树和2-3-4树都是B树的特例
节点最大的孩子数目称为B树的阶, 所以2-3树是3阶B树, 2-3-4树是4阶B树
用阶定义的 B 树:
- 树中每个节点最多含有 m 个孩子, m >= 2
- 除根节点和叶子节点外, 其它每个节点至少有
ceil(m/2)个孩子(其中ceil()是取上限函数) - 若根节点不是叶子节点, 则至少有 2 个孩子(特殊情况:没有孩子的根节点, 即整棵树只有一个根节点)
- 所有叶子节点都出现在同一层
- 每个非终端节点中包含有 n 个关键字信息:
(n,P0,K1,P1,K2,P2,......,Kn,Pn)其中- a) Ki (i=1…n) 为关键字, 且关键字按顺序升序排序 K(i-1) < Ki
- b) Pi 为指向子树的节点, 且指针 P(i-1) 指向子树中的所有节点的关键字均小于 Ki, 但都大于 K(i-1)
- c) 关键字的个数 n 必须满足:
ceil(m/2)-1 <= n <= m-1
注意 B 树中每一个节点能包含的关键字数有一个上界和下界, 这个下界可以用一个称作 B 树的最小度数表示
一棵含有 N 个总关键字数的 m 阶的 B 树的最大高度: log_ceil(m/2) (N+1)/2+1
B树广泛用于文件系统及数据库中, 通过对每个节点存储个数的扩展, 使得对连续的数据能够进行较快的定位和访问, 能够有效减少查找时间, 提高存储的空间局部性从而减少IO操作, 实际的 B 树节点中关键字很多, 可能是从几个到几千个, 节点越多,B 树比平衡二叉树所用的磁盘 IO 操作次数将越少, 效率也越高
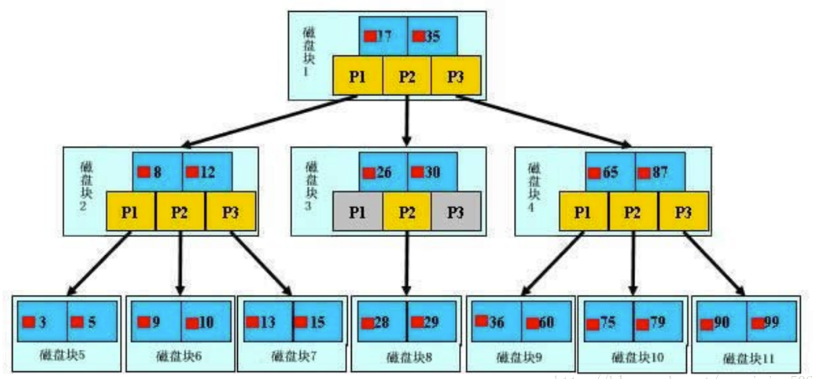
实际使用场景如:
- Windows: HPFS 文件系统
- Mac: HFS, HFS+ 文件系统
- Linux: ResiserFS, XFS, Ext3FS, JFS 文件系统
- 数据库: Oracle, MySQL, SQLServer 等
B+树
是应文件系统所需而产生的B树的变形树
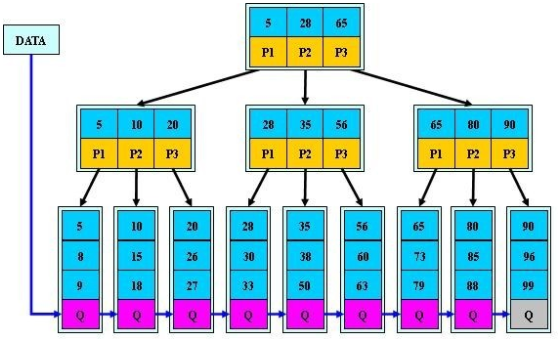
B+树的三个特点:
- 关键字数和子树相同
- 非叶子节点仅用作索引, 它的关键字和子节点有重复元素
- 叶子节点用指针连在一起
m阶的B+树和m阶的B树的异同点在于:
- 有n棵子树的节点中含有n-1个关键字; (有争议, 一说B+树n棵子树的节点中含有n个关键字)
- 所有的叶子节点中包含全部关键字的信息, 及指向含有这些关键字记录的指针, 且叶子节点本身依关键字顺序链接
- 所有的非终端节点可以看成是索引部分, 非终端节点不含需要查找的数据
B+树的结构比B树, 在文件系统数据库当中更有优势, 原因如下:
1. B+树的磁盘读写代价更低
B+树内部节点并没有指向关键字具体信息的指针, 其内部节点相对B树更小, 于是同一盘块能容纳的关键字数量也多, 减少了读入内存的开销
2. B+树的查询效率更加稳定
路径上的节点并不是最终指向内容的, 只是叶子节点关键字的索引, 任何关键字查找都必须走一条从根节点到叶子节点的路, 所有关键字查询的路径长度相同, 导致每个数据的查询效率相当
3. B+树更有利于数据库扫描
B树虽然提高了磁盘IO, 但没有解决元素遍历效率低下的问题, 而B+树只需要遍历叶子节点就可以解决对全部关键字信息的扫描, 对数据库中频繁使用 range query 时, B+树有更高的性能
在有数据库索引的情况下, order by 索引的值, 返回速度特别快, 因为它并没有给你真的排序, 只是遍历树而已
B树优于B+树的地方:
在成功查询时特别有利, 因为树的高度总体要比B+树矮, 有很多基于频率的搜索是选用B树, 越频繁 query 的节点越往根上走, 前提是需要对 query 做统计, 而且要对 key 做一些变化
工程实践中的特性
B树的中间节点比B+树多存了value, 同样出度的情况下, 节点更大, 相对来说CPU cache命中率不如B+树
在实际场景, 无论B树还是B+树, 树根和上面几层因为被反复query, 所以这几块基本都在内存中, 不会出现读磁盘 IO, 一般启动时就会主动换入内存
另外, B+树的扫描特性 (扫描链表串起来的叶子节点) 在无锁情况下是很难做的, 目前见到的无锁B+树叶子节点都是不串起来的
B*树
B*树是B+树的变体, 在B+树的基础上 (所有的叶子节点中包含了全部关键字的信息, 及指向含有这些关键字记录的指针), B*树中非根和非叶子节点再增加指向兄弟的指针
B*树节点已满时, 会检查兄弟节点是否满 (因为每个节点都有指向兄弟的指针), 如果兄弟节点未满则向兄弟转移关键字, 如果兄弟节点已满, 则从当前节点和兄弟节点各拿出1/3数据创建一个新节点
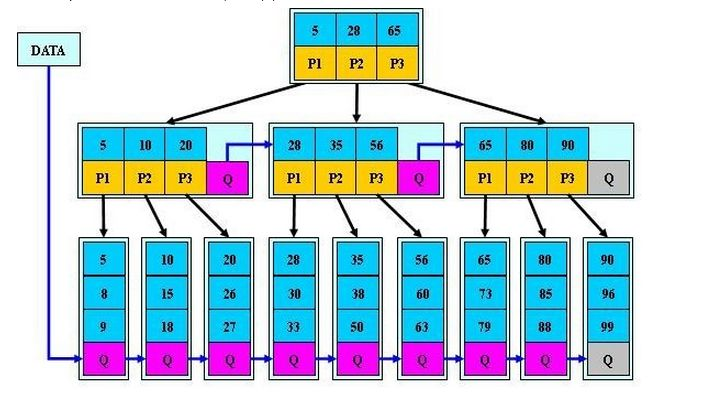
B+树 vs B*树的分裂
B+树的分裂: 当一个节点满时, 分配一个新的节点, 并将原节点中1/2的数据复制到新节点, 最后在父节点中增加新节点的指针, B+树的分裂只影响原节点和父节点, 不会影响兄弟节点, 它不需要指向兄弟的指针
B*树的分裂: 当一个节点满时, 如果它的下一个兄弟节点未满, 那么将一部分数据移到兄弟节点中, 再在原节点插入关键字, 最后修改父节点中兄弟节点的关键字(因为兄弟节点的关键字范围改变了), 如果兄弟也满了, 则在原节点与兄弟节点之间增加新节点, 并各复制1/3的数据到新节点, 最后在父节点增加新节点的指针
所以, B*树分配新节点的概率比B+树要低, 空间使用率更高
R树
R树是B树的高维度扩展, 解决了在高维空间搜索等问题, 它把B树的设计思想扩展到了多维空间, 把索引替换为 Minimal Bounding Rectangle, MBR
大致是:
- 过程节点只存索引, 只在叶子节点存数据
- 对于二维数据, 索引是恰好能包裹住数据的最小矩形 (对于三维数据, 索引是长方体, 对于高维类推)
- 查找时, 只查找给定数据跟索引在 MBR 上有重叠的分支
- 插入时, 如果遇到要扩充 MBR 的情况, 就选择使 MBR 变化最小的分支
R树的查找过程
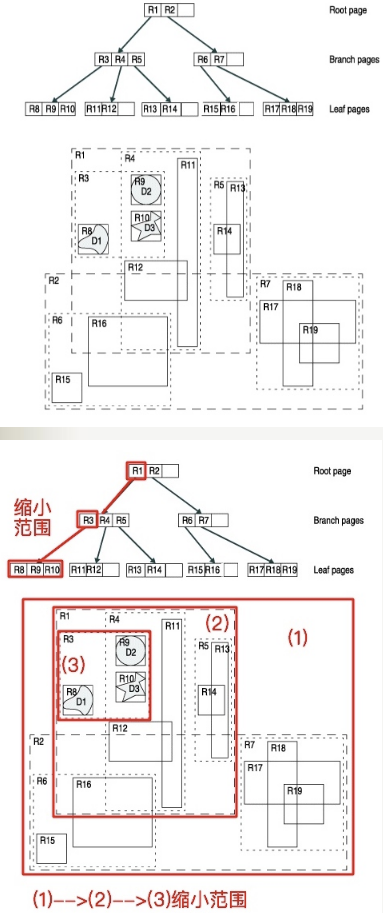
从R树的角度返回来看B树, 可以认为B树是一维的线段树, 但是完全照搬R树的实现, 会导致线段可能重叠
R树更准确的定义:
- 所有叶子节点包含有m至M个记录索引, 通常
m=M/2, 特殊的, 作为根节点的叶子节点的记录数可以少于m - 对于所有在叶子中存储的记录, I是最小的可完全覆盖这些记录的矩形
- 每一个非叶子节点拥有m至M个孩子节点 (除非它是根节点)
- 对于在非叶子节点上的每一个条目, i是最小的可完全覆盖这些条目的矩形 (同性质2)
- 所有叶子节点都位于同一层, R树为平衡树
R树在现实领域中的例子: 查找20英里以内所有的餐厅, 如果没有R树, 就得把餐厅的坐标 (x,y) 分为两个字段存放在数据库中, 这样需要遍历所有餐厅获取其位置信息, 然后计算是否满足要求, 如果一个地区有100家餐厅的话, 就要进行100次位置计算操作, 应用到谷歌地图这种超大数据库中必定不可行
四叉树 vs R树
四叉树 (Quadtree) 即二叉树在划分方式上的扩展, 二叉树每次将空间减至一半, 而四叉树每次将空间划分为四个象限
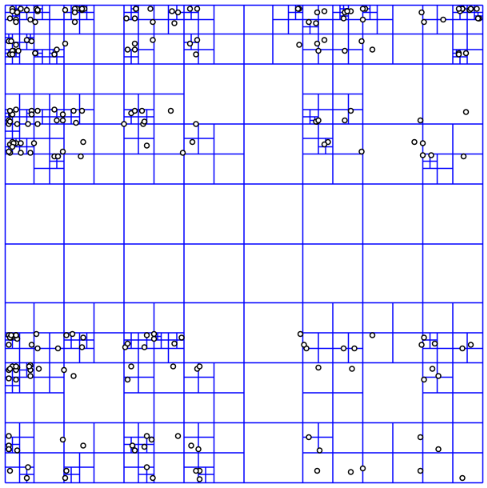
R树:
- 平衡, 没有空叶, 树高度更小
- 在磁盘上有明显优势 (类似于在磁盘上倾向于使用B树, 而不是二叉树)
- 插入或删除可能导致索引重组
四叉树:
- 简单, 约束少
- 对于高变化频率的且分布均匀的数据, 性能比R树好
- 不平衡, 有空叶
Trie树
Trie树 (也叫字典树, 前缀树) 是自然语言处理中最常用的数据结构, 很多字符串处理任务都会用到, Trie树每个节点只包含一个字符, 从根节点到叶节点, 路径上经过的字符连接起来构成一个词
例子:
Root
/ | \
/ | \
清 中 华
/ \ | |
华 新 华 人
/ \ | | |
1 大 3 4 5
|
学
|
2
Trie树可以看做普通的树对 “键的管理” 的改进: 键不是直接保存在节点中, 而是由节点在树中的位置决定, 一个节点的所有子孙都有相同的前缀, 也就是这个节点对应的字符串
类比字典的特性: 在字典里查找晃 (huang) 这个字的时候, 会发现它附近都是读音为 huang 的, 再往前翻会看到读音前缀为 huan 的字, 再往前是读音前缀为 hua 的字… 我们在查找时, 根据 abc…xyz 的顺序找到 h 前缀的部分, 再根据 ha he hu 找到 hu 前缀的部分… 最后找到 huang, 我们会发现, 越往后其读音前缀越长, 查找也越精确, 这种类似字典的树结构就是字典树
类比有限状态自动机的特性: Trie树也可以看做是个有限状态自动机 (Definite Automata, DFA), 从 Trie 树的一个节点 (状态) 转移到另一个节点 (状态) 的行为完全由状态转移函数控制, 而状态转移函数本质上是一种映射, 在Trie树的 “双数组实现” 中, 能更好的理解它为什么是个有限状态自动机
早期的 “标准 Trie 树” (例如上图) 实现结构简单, 每个节点都由指针数组存储, 每个节点的所有子节点都位于一个数组之中, 每个数组都是完全一样的, 对于英文每个数组有 27 个指针, 是典型的以 “空间换时间” 的实现
图示 abc、d、da、dda 四个字符串构成的 “标准 Trie 树”, 如果是字符串, 会在节点的尾部进行标记, 没有后续字符的 branch 分支指向NULL
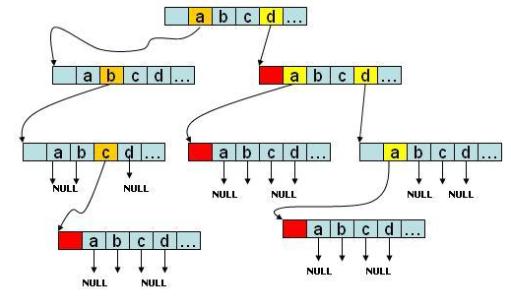
之后又产生了 “List Trie 树” 和 “Hash Trie 树”:
- List Trie 树: 把 “标准 Trie 树” 的定长数组改为链表, 省空间, 但是查询变成了 O(m)
- Hash Trie 树: 把 “标准 Trie 树” 的定长数组改为键值对, Hash 本质上是一个平衡 “数组 (查询快增删慢)” 和 “可变数组 (增删快查询慢)” 优缺点的数据结构
比较复杂的实现是 “Double-array Trie 树”: 小白详解 Trie 树
双数组 Trie 树和经典 Trie 树一样也是用数组实现, 但它将所有节点状态都记录到一个数组中 (Base Array)
首先需要对字符编码:
清-1,华-2,大-3,学-4,新-5,中-6,人-7
然后维护一个数组叫 base array, 其每个 “position” 对应 “节点”, 每个 “position 的值” 对应 “下一个节点的转移基数”
char code: - - 1 2 2 2 3 6 5 7 4
char code value: - - 清 华 华 华 大 中 新 人 学
base array position: 0 1 2 3 4 5 6 7 8 9 10
base array value: 1 - 3 2 2 3 6 2 3 2 6
这里需要两个函数, base(2) = 3 表示取 base array 对应位置的值, code("华") = 2 表示取事先决定好的字符编码
构造好这个结构之后, 想查找 “清华大学” 这个词在不在树里? 步骤是:
首先查找 清: base(root) + code(清) = 2, 所以 清 在 base array 的 position 2
然后查找 华: base(清) + code(华) = 5, 所以 华 在 base array 的 position 5
如此反复, 直到查完
注意这里有三个 华, 其实对应着Trie树的三个不同节点的 华
Root
/ | \
/ | \
清 中 华
/ \ | |
华 新 华 人
/ \ | | |
1 大 3 4 5
|
学
|
2
另一个查询的例子:
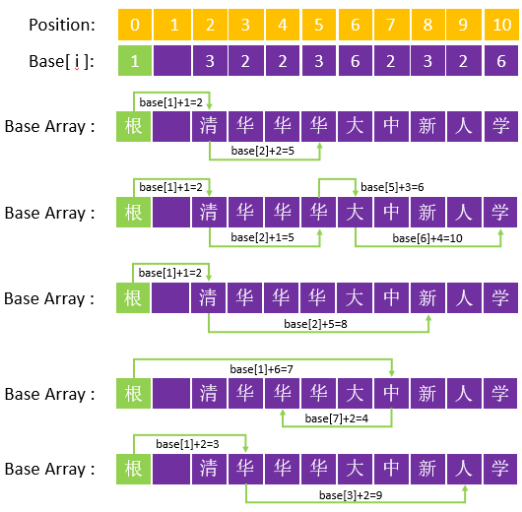
双数组 Trie 树的另一个数组, 是与 base array 等长的 “check array”, 作用是标识出 base array 中每个状态的前一个状态, 以检验状态转移的正确性, 也可以说 check array 记忆了这条转移路径上的父节点, 如果没有 check array, 就无法检验当前节点是否与父节点处于同一链路
Trie 树是以信息换时间的数据结构, 其查询的复杂度为O(m)
怎么理解 “信息换时间”, 跟交叉熵有关?
总结使用场景
AVL树, 红黑树, B树, B+树, Trie树都分别应用在哪些现实场景中?
AVL 树:
最早的平衡二叉树之一, 应用相对其他数据结构比较少, Windows 对进程地址空间的管理用到了 AVL 树, 追求局部而不是非常严格整体平衡的红黑树, 当然如果场景中对插入删除不频繁, 只是对查找特别有要求, AVL 还是优于红黑
红黑树:
平衡二叉树, 工业界最主要使用, 平衡度不像 AVL 那么好, 最差情况从根到叶子的最长路是最短路的两倍, 但旋转保持平衡次数较少
- 广泛用在 C++ 的 STL 中, 如 map 和 set 都是用红黑树实现
- 著名的 linux 进程调度 Completely Fair Scheduler, 用红黑树管理进程控制块
- epoll 在内核中的实现, 用红黑树管理事件块
- nginx 中, 用红黑树管理 timer 等
- Java 的 TreeMap 实现
B/B+树:
分支多层数少, 一般用在磁盘文件组织, 数据索引, 数据库索引
Trie树:
不平衡也不一定有序, 用在统计和排序大量字符串, 模式匹配、正则表达式, 本身是一种有限状态自动机
如果字符串长度是固定或说有限, 那Trie的深度是可控的, 需要针对实际应用来设计自己的Trie树
从工程角度区分红黑树与B+树的应用场景, 红黑树一个 node 只存一对 kv, 因此可以使用类似嵌入式链表的方式实现, 数据结构本身不管理内存, 比较轻量级, 使用更灵活也更省内存, 比如一个 node 可以同时存在若干个树或链表中, 内核中比较常见, 而B+树由于每个 node 要存多对 kv, node 结构的内存一般就要由数据结构自己来管, 是真正意义上的 container, 相对嵌入式方法实现的红黑树, 好处是用法简单, 自己管理内存更容易做 lockfree, 一个 node 存多对 kv 的方式 cpu cache 命中率更高, 所以用户态实现的高并发索引一般还是选B+树
